
AI is a key technology used in the security software landscape, yet what is often overlooked is the fact that AI itself is becoming an increasingly vulnerable attack surface, due to technical challenges:
- AI systems operate as black boxes.
- AI systems rely on data pipelines that can be poisoned.
To protect their machine learning models, companies are using enterprise-grade AI safety frameworks (e.g., Anthropic’s Constitutional AI) and increasingly adapting MLSecOps tools. After spending several hours reviewing product and tool documentation, I listed the best open source tools and commercial MLSecOps tools.
What is MLSecOps?
MLSecOps (Machine Learning Security Operations) is the practice of securing the entire machine learning lifecycle, from data collection and model development to deployment, monitoring, and decommissioning—integrating security as a continuous, automated part of MLOps, just like DevSecOps does for software.
→ For more, see: MLOps case studies.
Key goals of MLSecOps
- Protect ML systems from data poisoning, model theft, prompt injection, adversarial attacks.
- Ensure trust, compliance, and auditability in AI models.
- Embed security checks and monitoring throughout the ML pipeline.
MLSecOps pipeline:
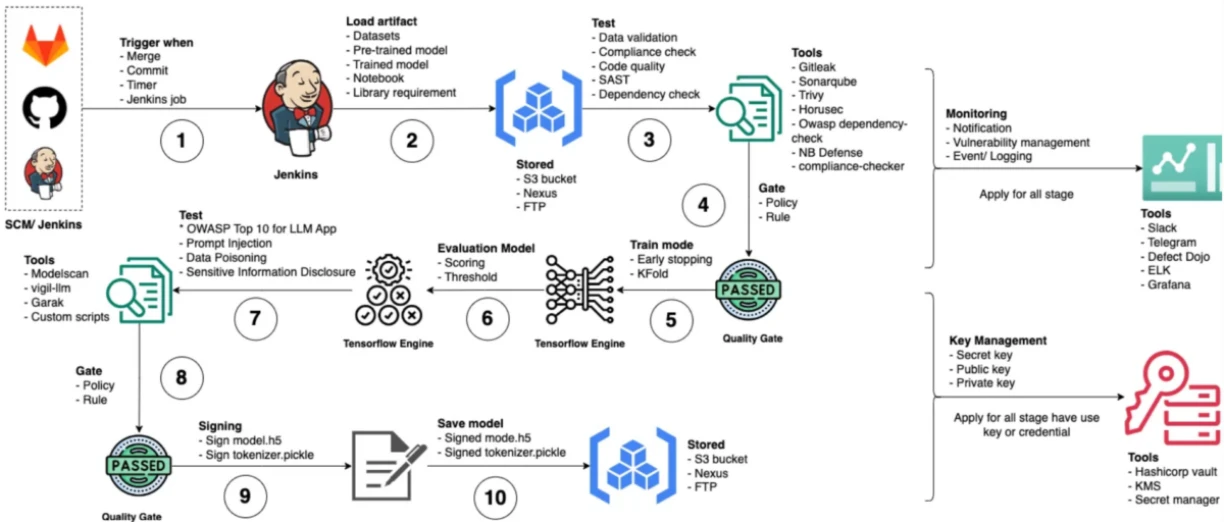
Model building:
These tools are used during the machine learning (ML) development lifecycle, specifically when creating, training, and deploying AI models.
Last Updated at 04-18-2025
- Protect AI ModelScan: Scans statistical and machine learning models to determine if they contain unsafe code.
- Protect AI NB Defense: A JupyterLab extension and CLI tool for AI vulnerability management.
- IBM Adversarial Robustness Toolbox (ART): A Python library for ML defense against adversarial threats, hosted by the Linux AI & Data Foundation. Defends against adversarial attacks such as evasion, or poisoning via pre-built defenses/metrics, and red and blue teaming.
- Azure PyRIT: A Python risk identification tool for generative AI (PyRIT) built to proactively identify risks in generative AI systems (e.g., data poisoning).
- Privacy Meter: Provides auditing data privacy in statistical and machine learning algorithms (classification, regression, computer vision, and natural language processing) against inference attacks.
- AI audit: A Python library for ML bias testing, offered by pymetrics.
- PrivacyRaven: Assesses the risk of a model being exposed to privacy attacks such as model extraction and membership inference attacks.
Model consumption:
These tools are used after a machine learning model has been built and deployed.
Last Updated at 04-18-2025
- Agentic security: Protects AI systems from multimodal attacks across text, images, and audio, multi-step jailbreaks, and fuzzing. Provides API integration & stress testing.
- Protect AI LLM Guard: Detects, redacts, and sanitizes LLM prompts. It also provides Personal Identifiable Information (PII) redaction and data leakage detection. → Also see: LLM security tools.
- TF-encrypted: A framework for encrypted deep learning in TensorFlow, without requiring expertise in cryptography. By building directly on TensorFlow, it offers a framework with a high-level interface.
- Agentic security: Protects AI systems from multimodal attacks across text, images, and audio, Multi-step jailbreaks, and fuzzing. Provides API integration & stress testing.
- Protect AI LLM Guard: Detects, redacts, and sanitizes LLM prompts. It also provides Personal Identifiable Information (PII) redaction and data leakage detection.
- Protect AI ModelScan: Scans statistical and machine learning models to determine if they contain unsafe code.
- Protect AI NB Defense: A JupyterLab extension and CLI tool for AI vulnerability management.
- Vigil: A Python library and REST API for detecting prompt injections, jailbreaks, and other potentially large language model (LLM) inputs.
- Garak: A Python package for the vulnerability scanning and analysis of LLMs for red teaming. Provides pre-defined vulnerability scanners for LLMs to probe for hallucinations, misinformation, harmful language, jailbreaks, and vulnerability to various types of prompt injection.
- NVIDIA NeMo-Guardrails: Enables developers building LLM-based applications to add programmable guardrails between the application code and the LLM. Provides mechanisms for protecting an LLM-powered chat application against common LLM vulnerabilities, such as jailbreaks and prompt injections.
* AI red teaming is a structured process simulating adversarial attacks on AI systems to identify vulnerabilities.
** AI firewall enforcement is a firewall for AI systems. It sits between the user and the model, analyzing prompts and responses to block harmful prompt injections and enforce usage policies, etc.

Protect AI
Secures entire AI development lifecycle (AI-SPM), including model training and AI data governance. Offers three commercial MLSecops tools:
- Guardian for zero trust for AI models
- Layer for end-to-end LLM security and governance monitoring
- Recon for automated red teaming
Features:
- ML model development security: Ensures secure workflows during model training and deployment
- Data access control: Prevents unauthorized exposure of sensitive information in LLM applications
- Proactive vulnerability discovery: Identifies LLM weaknesses via red teaming and adversarial testing
- AI lifecycle risk management: Enables continuous risk assessment and mitigation across all AI stages
Mindgard
Focus on red teaming during development, vulnerability assessment, and model hardening.
Features:
- Broad testing capabilities: Covers multi-modal GenAI, LLMs, audio, vision, chatbots, and agent-based applications
- MLOps compatibility: Integrates into existing MLOps pipelines for streamlined security testing
- Runtime protection: Enables real-time monitoring and threat defense for deployed AI systems
- Flexible deployment options: Supports deployment in cloud, on-premise, and air-gapped environments
AIShield
API based AI Security vulnerability assessment and defense. Best for analysis of AI/ML models.
Features:
- Model scanner: Auto-discovers models and notebooks, performs deep vulnerability scans.
- ML red teaming: Simulates attacks to detect adversarial threats, model theft, and poisoning.
- LLM red teaming: Finds prompt injection and jailbreak risks in LLMs.
- ML firewall: Real-time detection and blocking of adversarial ML threats.
- GenAI guardrails: Custom filters for GenAI, including bias checks and PII anonymization.
CalypsoAI
Red teaming during development, governance for model selection, and risk assessment.
Features:
- Inference Red-Team: Agent-driven red teaming to proactively uncover and resolve AI vulnerabilities.
- Inference Defend: Real-time, adaptive defenses that evolve alongside AI threats.
- API First: Built for easy integration and scalable deployment via APIs.
- SIEM/SOAR compatible: Connects with existing security operations platforms.
HiddenLayer
HiddenLayer’s approach is built on the MITRE ATLAS framework and emphasizes delivering real-time visibility into a model’s health and attack surface, without requiring direct access to the model itself or its training data.
Features:
- AI detection & response: Detect and respond to suspicious activity around your AI assets.
- Security scan: Scan and discover your AI assets.
Adversa
Provides an AI red teaming platform for AI and GenAI models, applications, and agents.
- LLM threat modeling: Risk profiling tailored to your LLM use case—consumer, customer, or enterprise—across any industry.
- LLM vulnerability audit: Audits against hundreds of known LLM threats, including the OWASP LLM Top 10.
- LLM red teaming: Attack simulations to uncover unknown and bypassable threats.
Prisma Cloud AI-SPM
Supports scanning for Amazon, Google Cloud, and Azure AI services to discover AI content.
Features:
- AI asset discovery: Automatically identifies AI models, data, and services across cloud environments.
- Security posture management: Monitors AI systems’ configurations, permissions, and data flows.
Apex
Agentless protection for LLM apps, copilots, GenAI portals, and runtime enforcement.
Features:
- AI threat detection: Detects and defends against attacks and vulnerabilities unique to AI systems.
- Automated policy enforcement: Ensures security and privacy standards are consistently met.
- AI activity monitoring: Provides full visibility into how AI systems are accessed and used.
- Sensitive data protection: Prevents exposure and leakage of confidential or personal information.
Lakera
Detects jailbreaks and prompt attacks on LLM agents. Best for Generative AI & model misuse protection. Products:
- Lakera Guard: Secures your AI agents by detecting and preventing malicious behavior in real time.
- Lakera Red: Identifies AI risks through red teaming and simulation of real-world threats.
- Lakera Gandalf: Provides AI security training to educate your team.
Traceable AI
Secures API-level integrations and protects against misuse of AI/LLM-driven APIs.
Features:
- API discovery & risk Assessment: Automatically identifies APIs and evaluates their risk posture.
- Attack prevention: Blocks threats that can lead to data leaks or unauthorized access.
- Threat analytics: Delivers insights into API activity and attack patterns.
Varonis
Offers a security platform built on a DSPM foundation, with an MLSecOps focus to assist development teams.
Features:
Aim Security
Real-time access governance, shadow AI discovery, and policy enforcement during model usage. Protects LLMs and Copilots.
Features:
- AI app inventory – Discovers and catalogs all AI applications across the organization.
- Data flow visibility – Detects how data interacts with AI/LLMs, including storage and learning behaviors.
- Compliance enforcement: Monitors AI adoption and enforces data privacy and GenAI regulations.
Further Reading
For more on MLOps, see:
External Links
#Top #Open #Source #Commercial #Tools




